

Emerging memristors are novel circuit elements, originally described as the “fourth missing circuit
element” and considered today as the future of nonvolatile memory. Different memristors have been
developed and simulatively characterized by the Technion’s ASIC² research group, headed by Prof.
Shahar Kvatinsky. Current Compliance (CC) is a factor that can significantly influence the memristive devices
performance.
State-of-the-art apparatus propose CC circuit with response time of 100𝜇Sec to 1mSec, this slow
response time may cause undesired behavior of the memristive devices or even damage the device.
Our target is to potentially improve the measurement setup of research memristive devices by
designing a small CC circuit.

Traditional approaches to storing secret keys in memory for cryptographic applications are
susceptible to physical attacks when an attacker gains access to the storage medium.
To address this issue, physically unclonable functions (PUFs) have emerged as a novel concept for
secure key storage. PUFs store the cryptographic key as unique analog identifiers within the hardware, rather than in
memory elements, making them resilient against physical attacks.
In this research, we propose the study of novel coating-based PUFs that leverage nanoscale
inhomogeneity, randomness, and uniqueness in nanomaterials and nanostructures.
Our study encompasses the design, simulations, fabrication, and characterization of physically
unclonable coatings, along with the development of metrics to evaluate their effectiveness.

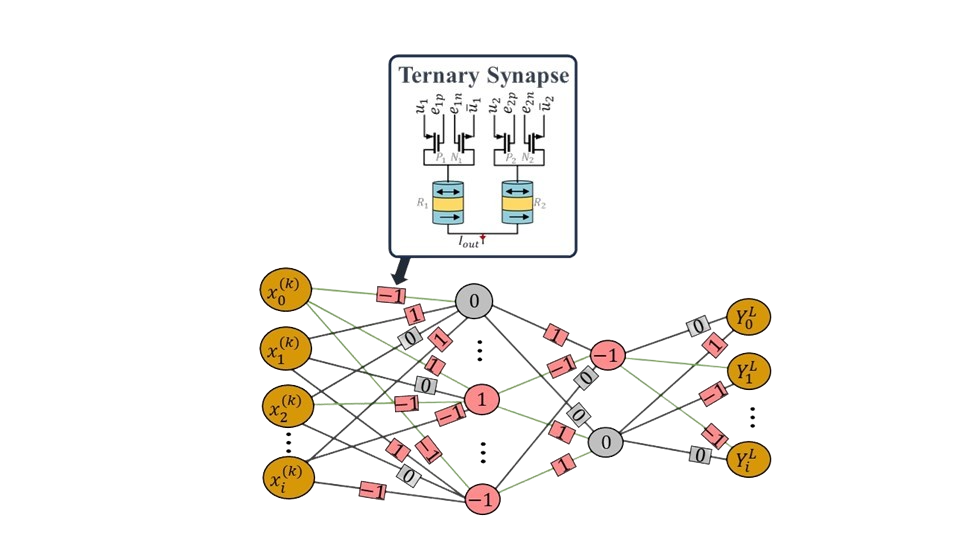
Recently, several different memristive technologies (ReRAM, CBRAM, PCM and STT-MRAM) have
emerged as promising candidates for digital and analog in-memory computation.
Deep neural networks (DNNs) are one of the main applications to benefit from analog in-memory
computation.
In this project you will simulate in-memory training of ternary neural networks (TNNs) with a magnetic
tunnel junction (MTJ) device.
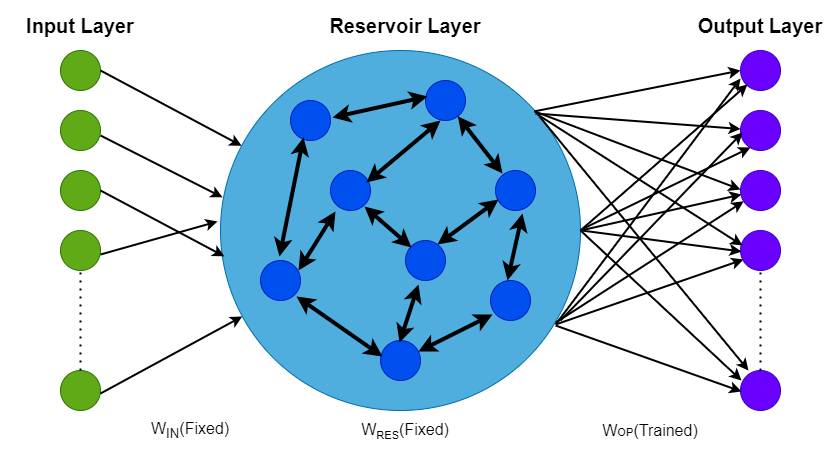
Reservoir computing is a kind of neural network architecture that is derived from recurrent neural
networks. It consists of a dynamic and non-linear reservoir module that maps the input data into high
dimensional space. This is then read-out using a fully connected readout layer. The advantage of this
network is that only the readout layer requires training, usually by regression.

